As we build cloud-based solutions, it’s very easy to “lift and shift.” That is, we can move workloads directly from a server or even a developer’s laptop to the cloud without putting much thought into it. Sometimes, this is by way of a VM, and sometimes, it’s a Docker container, but is this the most cost-effective way of managing cloud solutions for an MVP or small-scale startup?
Of course, the answer to that question depends. It depends on many factors.
How bespoke is the process? Most cloud vendors nowadays have solutions for many regular development patterns. Is there something already available that you could leverage?
If the cloud vendor does not offer a singular solution, could you split your processes into distributed ones? This may potentially create more complexity, but it may also introduce something else pretty cool about cloud solutions to your infrastructure: scalability.
If you do want or need to lift and shift, there are several other essential factors you need to take into account, the most important being security. Cloud vendors will essentially do all the underlying security patching for you in their managed offerings, but in your home-spun VM or Docker image, the onus is now on you to provide patches to the software and dependencies within the stack, and that can cause an exciting management headache. On top of that, how resilient is the service, and how does it scale? How does it deal with failover, upgrades and so on? This all matters both at the application and operating system level.
What are cloud-first concepts? Cloud-first concepts are the idea that, more often than not, it’s preferable that someone else manage the infrastructure your applications, data flows, storage or whatever depends on. This approach offers several benefits. Firstly, they’ll probably do better in better data centres with better tech. If you’re a bean counter, the costs may seem like you’re paying more, but how much do your developers cost? Do you have a systems administrator or SRE on the books already? If not, you may need one for a production system. So, on top of your initial costs, add on another $100k plus. But what if you took that same stuff and chucked it into a cloud? What if you only had to think about running, maintaining, supporting, or upgrading anything other than your own code? This is what we’re talking about with cloud-first concepts. It’s not just about cost, it’s about efficiency, scalability, and focusing on what you do best.
So, what can you swap in a regular data application pipeline? A regular data application pipeline typically includes components for data ingestion, processing, storage, and user interaction. For simplicity’s sake, let’s assume we’re working on AWS, but you could pick pretty much any vendor.
We’re going to start by sketching out what our non-cloud application stack might consist of.
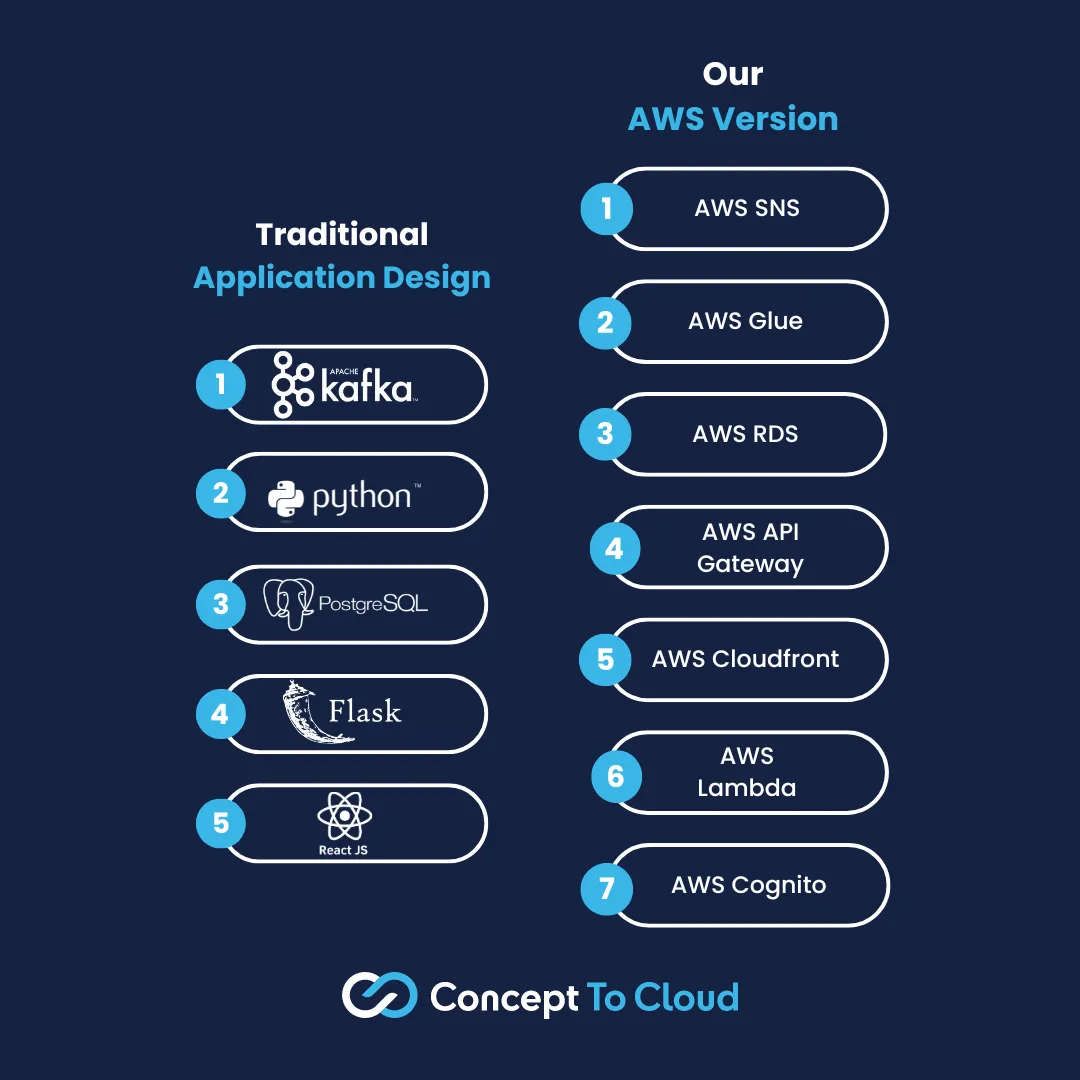
Let’s say we’ve got a stream of data coming in on the backend, stocks, because who doesn’t love a demo that tracks the stock market? Okay, so that stream comes in, let’s dump it into a Kafka queue to ensure we capture the information arriving before we process it.
From that, we’re then lifting the data from Kafka and running it out to a data store. Let’s keep this really simple and say we’re going to read the stream using a simple Python process, use Pandas to ETL it into a tabular structure, and then write it out to a Postgresql database.
So that’s our ingestion layer. Next, we’re going to deal with the user side, so let’s pretend our app has an API layer hooking into the Postgresql datastore, but it also needs a security layer, so you’ve got some authentication backend going there as well with users, groups, passwords etc being stored into a table in that same database. Finally, you need an application layer to deal with the API, so we’ve got a ReactJS UI that runs on a NodeJS server on a VM.
All sounds plausible. Cool!
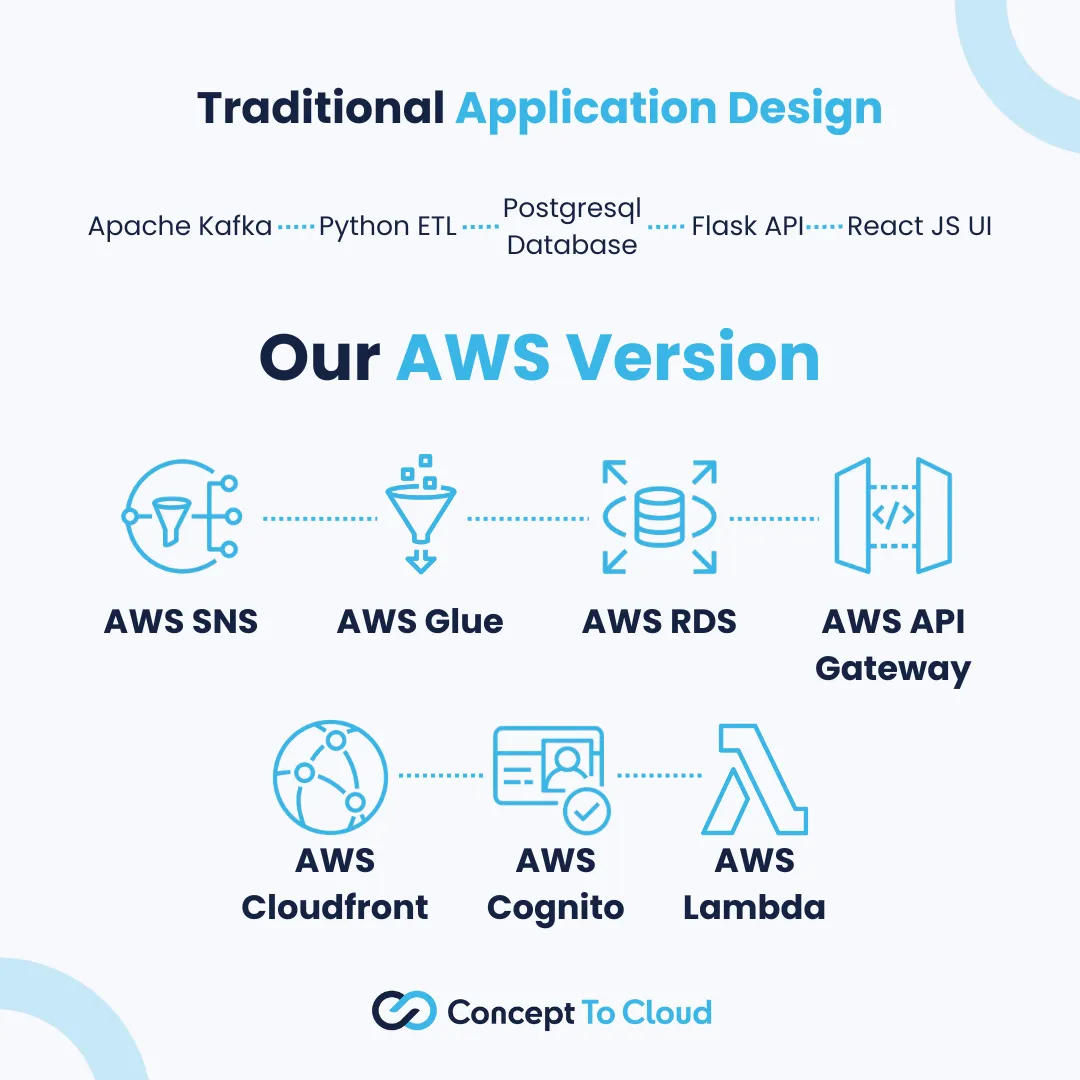
What does a cloud-first version of this app look like?
Let’s start at the backend again. Self-hosted Kafka? No thanks! Let’s decide what we want to use here. There are a few options, the most obvious being SNS or SQS; these give a very simple, comparatively, entry point into cloud-hosted messaging services. They have their drawbacks, though; compared to Kafka, they can’t handle the same level of throughput. So, if you were putting through high volume and low latency stock notifications, maybe there are better tools than these. There is, though, AWS Managed Streaming for Kafka. As the name suggests, this gives you a fully managed Kafka setup inside of AWS to stick your messages through. Cool!
So, we’ve got our cloud-first streaming pipeline sorted. What’s next? Next, we must work out how to ETL it into a data store. So, rather than doing batch reading, we want a streaming job to keep the flow of stocks coming into our data store. What should we look at? Rather than writing a blob of Python code to sit in a docker container and talk to Kafka, we could leverage something like AWS Glue to do the job for us. It has the concept of streaming jobs; these jobs can connect to both SNS and AWS Managed Kafka. We now can spin up an ETL that loads up the store, but usefully, it could also write to S3 or, in our case, out to a JDBC-backed datastore, which is perfect for our sample application that leveraged Postgres.
Of course, we want to run something other than just our Postgresql server; we want to have it managed for us. What we can use, again, depends on scale and volume, in its most simplistic terms, and what would cover the bulk of use cases. Amazon RDS, which comes in myriad flavors along with “serverless” and “non-serverless” versions, gives us a good storage engine. The other option is Amazon Redshift, which is designed far more for Analytical workloads, but depending on the queries being run, it might offer a performance improvement if the queries are more dashboardy in nature.
So, we’ve designed our cloud-first backend. How do we expose it to users?
It’s really tempting to lift and shift that Flask backend; believe me, I’ve done it often enough, but I also know it’s not always the most sensible option. How about we migrate to AWS API Gateway instead? This gives us a platform that scales and deals with all the networking intricacies on your behalf. How do you deal with the processing logic underneath the API? Depending on the architecture, there are a few ways to do this, but Lambda functions are a great low-cost solution. These can be written in various languages, and because they are “serverless”, they just cost money when executed. This means you pay nothing when the users aren’t hitting the platform.
“What about API security?” I hear you ask. The most obvious answer here, as we’re trying to keep everything constrained to AWS, is Cognito. AWS Cognito provides security services across publicly accessible endpoints and UIs to ensure your data doesn’t go missing. It also integrates easily into API Gateway and a myriad of other AWS services.
Alright, home leg, I promise! What about the UI? This is probably the easy part. Sometimes, it depends, but the best solution is to compile the app into a blob of Javascript and HTML and stick it into AWS Cloudfront. Cloudfront is a content delivery network which will push your UI to locations around the globe, and when users go visit your app, they are served the version closest to them, giving them the most responsive version of the app possible, and you’ve done nothing to configure it. Now, that sounds like a win to me!
As you can see, by taking an application and deconstructing its parts there’s often an offering, or multiple offerings for each part. By choosing them, if you’re moving to the cloud anyway, there’s a lot to say about the simplicity of leveraging these components. Of course, this doesn’t work for everyone by any means; maybe you have portability in mind or a process that doesn’t work anywhere other than inside a container. But if you’re a small shop needing to build out a service with minimal staff and support, then leverage what you can with your cloud vendor; with prudent execution, you’ll save a lot of money in the long run.
You can build a billion-dollar company with less than ten members of staff and superb execution on all fronts. This is important, and when developers are starting to crack out their IDEs for the first time, stop and think about the development and deployment targets because if they differ wildly, you probably need to put some thought into how best to align the two to help aid the developer and stop massive rewrites when the code hits the cloud.
Want to know how I know? Experience, and lots of it, good and bad.
Let me know what you think, what I’ve missed and if there’s more you would like to know!
If your company could use our expert knowledge in deploying and scaling systems, then book an introductory call and find out how Spicule can help.
Thanks for reading Idea Ignition: Fueling Startups from Concept to Cloud! Subscribe for free to receive new posts and support my work.

